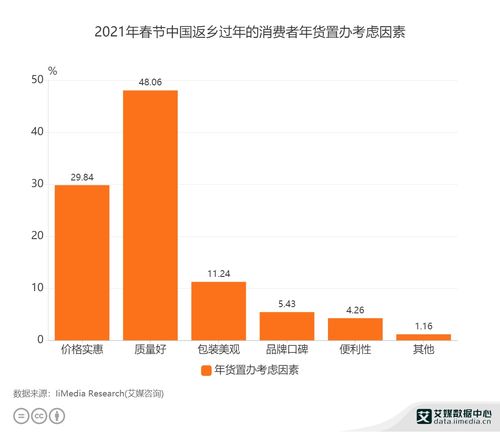
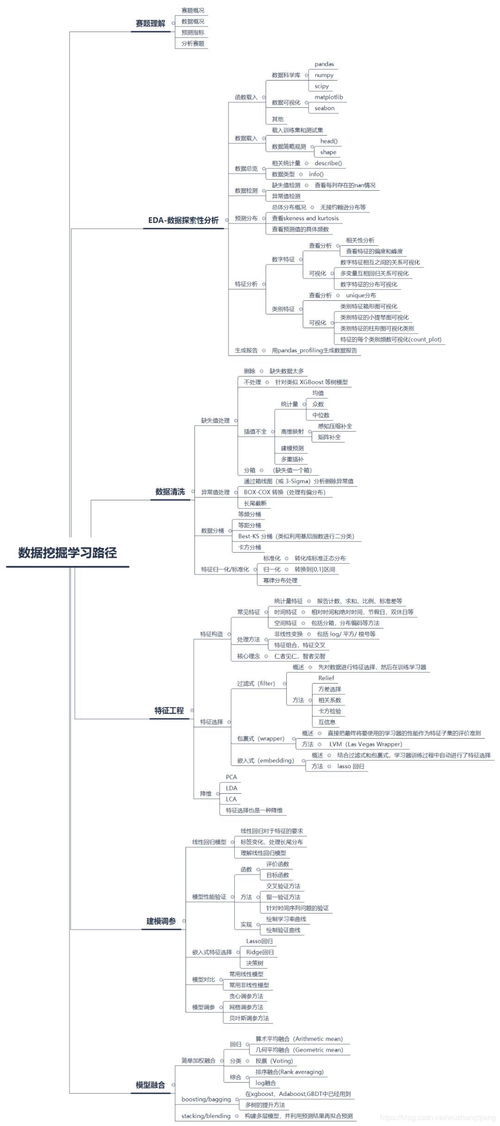
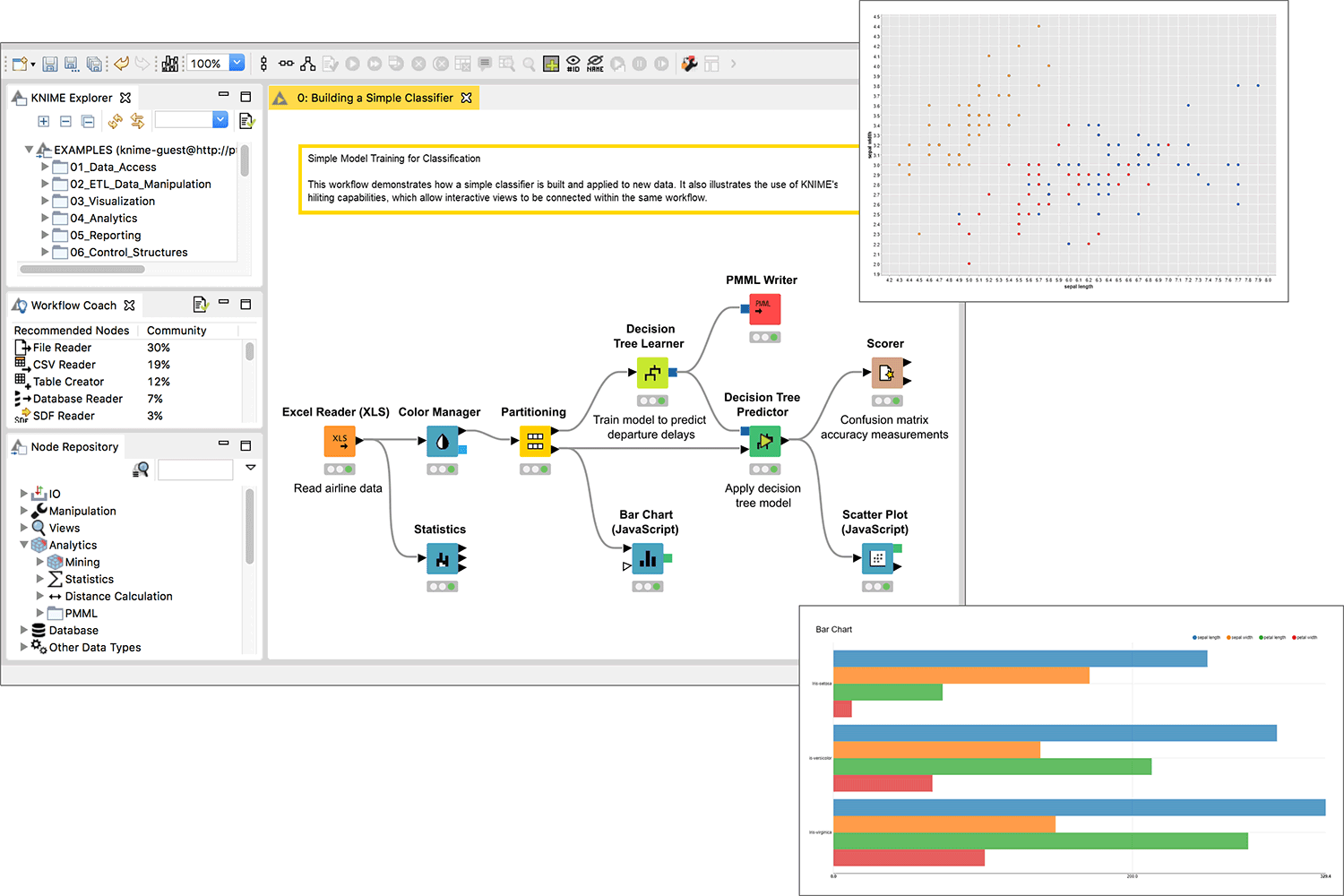
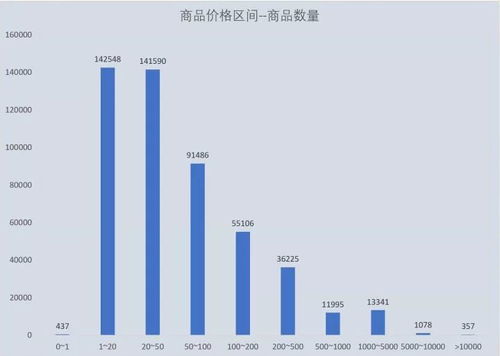
Python3数据分析与挖掘建模实战笔记 数据挖掘及分析核心概览

数据挖掘与分析作为从海量数据中提取有价值信息和知识的核心技术,在当今大数据时代扮演着至关重要的角色。借助Python3强大的生态系统(如Pandas、NumPy、Scikit-learn等库),我们可以高效地完成从数据预处理到模型构建的完整流程。
一、数据挖掘基本流程
- 业务理解与目标定义:明确分析目标,如用户分群、销量预测或欺诈检测。
- 数据收集与整合:从数据库、API或文件(CSV/Excel)中获取多源数据。
- 数据预处理:
- 缺失值处理:采用删除、均值填充或模型预测等方法。
- 异常值检测:使用箱线图、3σ原则或孤立森林算法识别。
- 数据标准化:Min-Max缩放或Z-score归一化消除量纲影响。
- 特征工程:构造衍生特征(如日期拆分为年/月/日)或编码分类变量。
- 探索性数据分析(EDA):
- 统计描述:df.describe()快速了解数据分布。
- 可视化分析:Matplotlib/Seaborn绘制散点图、热力图与分布直方图。
- 相关性分析:计算Pearson系数或使用热力图呈现特征关联。
二、常用挖掘建模方法
- 分类模型:
- 逻辑回归:适用于二分类问题,可输出概率预测。
- 决策树与随机森林:直观易解释,能处理非线性关系。
- 支持向量机(SVM):在小样本高维数据中表现优异。
- 聚类分析:
- K-Means:基于距离划分相似样本,需预先指定簇数量。
- DBSCAN:基于密度聚类,可自动识别噪声点。
- 关联规则:
- Apriori算法:挖掘“面包→牛奶”等频繁项集与关联规则。
- 时序预测:
- ARIMA模型:结合自回归与移动平均处理时间序列数据。
三、Python实战要点
1. 使用Pandas进行数据操作:
`python
import pandas as pd
df = pd.read_csv('data.csv')
df.fillna(df.mean(), inplace=True)
`
2. 模型训练与评估示例:
`python
from sklearn.modelselection import traintestsplit
from sklearn.ensemble import RandomForestClassifier
Xtrain, Xtest, ytrain, ytest = traintestsplit(X, y, testsize=0.3)
model = RandomForestClassifier(nestimators=100)
model.fit(Xtrain, ytrain)
print('准确率:', model.score(Xtest, y_test))
`
- 模型优化方向:
- 超参数调优:使用GridSearchCV或随机搜索。
- 特征选择:通过方差阈值、递归特征消除(RFE)提升效率。
- 集成学习:结合多个弱模型(如投票法)增强泛化能力。
四、实践注意事项
- 避免数据泄露:确保预处理步骤在训练/测试集分割后独立进行。
- 模型可解释性:优先选择逻辑回归等透明模型,必要时用SHAP工具解释黑盒模型。
- 业务闭环:将挖掘结果转化为可执行的业务策略,如针对高价值用户设计营销活动。
通过系统化流程与Python工具的结合,数据挖掘能够将原始数据转化为驱动决策的智慧,而持续迭代与业务反馈是模型保持生命力的关键。
如若转载,请注明出处:http://www.appzhiku.com/product/14.html
更新时间:2026-06-19 13:25:30